Ho il piacere di essere l’Account Systems Engineer di uno dei principali Gruppi Industriali italiani.
Da questo osservatorio privilegiato posso notare alcuni fenomeni recenti che interessano principalmente il mondo applicativo, ma che hanno già o avranno ricadute a breve sul mondo IT ed in particolare per quanto ci riguarda, sulla componente Storage.
Li elenco di seguito:
- Microsoft Exchange 2013
- SAP Hana
- Oracle & Exadata
Microsoft
Con l’ultima versione di Exchange è particolarmente aggressiva sui Clienti con l’approccio basato su “Server e dischi interni”. L’idea alla base del loro messaggio è semplice : il nuovo Exchange è talmente leggero e prestazionale che non serve avere infrastrutture Storage dedicate (o condivise) tutto puo’ essere tranquillamente gestito da soluzioni a basso costo locali, tanto ci sono meccanismi di replica nativa. La ridondanza è quindi garantita.
La risposta di EMC è ovviamente diversa: la soluzione DAS/dischi interni fa crescere il TCO (Total Cost of Ownership) rispetto a soluzioni SAN e moltiplica inutilmente la quantità di dato oggetto di replica (un recente documento di Wikibon illustra in dettaglio come questo si realizza).
E’ stato infatti dimostrato come nelle soluzioni EMC, siano esse basate su VNX o VMAX, il numero delle copie necessarie per l’affidabilità del dato si riduce drasticamente, grazie alla resilienza delle citate piattaforme Storage (rispettivamente 99,9998% e 99,999%) .
Per raggiungere un elevato livello di
Flessibilità e Agilità occorre utilizzare funzionalità di Virtualizzazione, siano esse VMware o Hyper-V, che richiedono ‘Shared Storage’ e che sono sfruttate al meglio nelle configurazioni SAN.
Affidabilità e DR: lo ‘Shared Storage’ abilita anche ad una singola strategia di DR (RecoverPoint è in questo ambito la tecnologia ideale) e permette la consistenza anche tra differenti applicazioni.
A cio’ si aggiunge la possibilità di ottenere un RPO (Recovery Point Objective) ed RTO (Recovery Time Objective) di zero (0), utilizzando la tecnologia VPLEX per avere accessi active/active sia locali che Metro.
Infine da tenere in considerazione che VNX si integra con
AppSync e Kroll ItemPoint per ottenere un granulare restore/recovery e che gli Storage Pool di VNX sono uno strumento estremamente semplice e flessibile per gestire le capacità e le crescite degli ambienti Exchange, specialmente quelli medio grandi.
La possibilità di usufruire del medesimo Storage già esistente ed utilizzato da altre applicazioni, aggiungendo il nuovo ambiente Exchange significa un rapido tempo di implementazione e poter beneficiare di soluzioni Storage ad alto valore quali per esempio , il Virtual Provisioning ed il FAST (Fully Automated Storage Tiering) e la FAST Cache (VNX).
In presenza di una nuova infrastruttura Exchange 2013, un altro approccio per competere ed ottenere i migliori risultati di TCO, è quello di posizionare una soluzione basata su multipli VNX di fascia entry ( il VNX5200 o VNX5300), che permettono di ottenere un costo di acquisizione interessante rispetto al sistema di fascia alta VNX (7500, 7600 o 8000) ed al contempo quindi, pur avendo le medesime protezioni ed affidabilità dei sistemi maggiori, hanno un prezzo di ingresso piu’ simile a quello delle architetture proposte da Microsoft /DAS-dischi interni.
Sap Hana
L’evoluzione di SAP verso le applicazioni In-Memory introducono sicuramente notevoli vantaggi prestazionali per il Business.
E’ vero infatti che i valori ottenuti con questa applicazione raggiungono livelli molto interessanti. Per contro, la componente Storage tende a diventare poco significativa e si arriva ad avere piccoli Storage integrati nella Soluzione (tipicamente VNX di fascia bassa), che spesso è “chiusa”, ovvero già definita in modo poco flessibile. In questi sistemi la potenza computazionale CPU / memoria tende ad avere la massima rilevanza.
EMC suggerisce per i Clienti Enterprise, di chiedere a SAP di partecipare al programma per i Clienti chiamato TDI (Tailored DataCenter Integration) .
Scopo di questa iniziativa è quello di certificare la soluzione SAP Hana su piattaforme Storage già presenti presso i Clienti. In questo modo si ottimizzano gli investimenti e si evitano di creare quei “Silos Verticali Applicativi” , il cui proliferare potrebbe creare difficoltà di gestione all’interno dei Data Center.
In questo caso si potrà beneficiare dei vantaggi di Virtual Provisioning, FAST, XtremCache, unitamente alle soluzioni di replica Storage del dato sincrona MirrorView/s o SRDF/S.
A ciò si aggiunge una soluzione di Backup certificata SAP Hana, basata su Data Domain, sistema di deduplica in-line Leader di Mercato (IDC PBBA* Giugno 2013,
58,9%).
La combinazione di questi fattori rende la proposizione EMC estremamente interessante e superiore a quanto offerto dai principali competitor.
Purpose Built Backup Appliance
Per quei Clienti che non possono partecipare al programma TDI, o preferiscono l’approccio “Appliance” con soluzioni Building Block, EMC propone l’ opzione VBlock entry level:
Questa soluzione basata sulla VBlock Converged Infrastructure permette di avere dei sistemi specializzati per SAP Hana (con all’interno sistemi VNX), “
Fully Certified”, “Factory Loaded” e pre “
Tested”
Completano la famiglia VBlock i sistemi di fascia alta, che arrivano a 9-12 nodi (4.0-5,5 TB) e 13-16 nodi (6.0 – 7.5 TB).
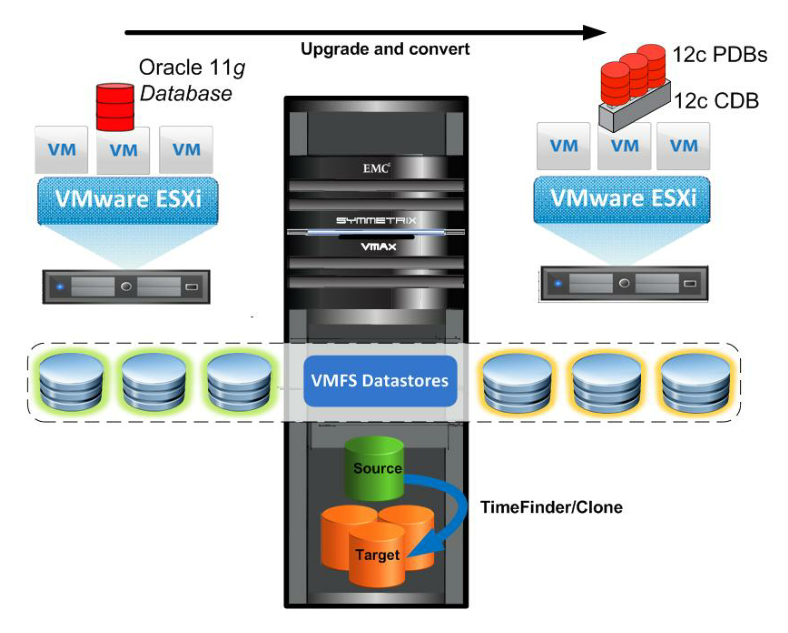
Oracle
Sta cercando aggressivamente di proporre soluzioni “Lock-in” (Exadata in primis), specialmente ai Clienti che hanno ELA/ULA significativi: all’interno del rinnovo delle licenze cercano di vendere o più spesso "regalare" un sistema Exadata.
Per il Cliente questo non è affatto un vantaggio: la soluzione “embedded” Exadata ha significativi punti di sofferenza, tra i quali spicca il tema del backup (e soprattutto del Restore), il Disaster Recovery, l’Affidabilità complessiva, il doversi legare a Release specifiche del Database ed a tecnologie “proprietarie” Lock-in HW e SW.
Invece EMC propone di appoggiare i DB basati su Oracle su piattaforme Storage estremamente
affidabili, sicure, veloci, dotate di meccanismi di backup con deduplica, completamente Open, siano esse VMAX o VNX. Ma ancora prima suggerisce ai Clienti di Virtualizzare e di risparmiare conseguentemente sui costi di Licenze, Operativi ed incrementando cosi’ la flessibilità degli ambienti.
La virtualizzazione degli ambienti Oracle infatti porta almeno 5 vantaggi:
- Riduzione dei costi associati alle Licenze (ROI)
- Prestazioni superiori e maggiore efficienza per i DBA
- Implementazione di nuovi ambienti (Server e Oracle) e dello Storage in pochi minuti
- Continuous Application Availability (in particolare con VPLEX e RecoverPoint, vedi sotto) multi Site, due o 3 siti.
- Standardizzazione (Virtualizzazione ed eventualmente soluzione VBlock Converged Infrastructure)
Tecnologicamente FAST e la FAST Cache apportano dei sostanziali benefici prestazionali richiesti, mentre l’ aggiunta della virtualizzazione di VPLEX, è in grado di offrire una superiore flessibilità operativa e di continuità del Business rispetto alle soluzioni Oracle Exadata. Mi riferisco in particolare alla possibilità di ottenere per ambienti Database Mission Critical, livelli di RPO ed RTO = zero, in congiunzione a RecoverPoint per la disponibilità applicativa continua sul 3° Sito.
Conclusioni:
Come emerge da questo sintetico documento, maturato da esperienze reali sul campo, la presenza di nuove proposte applicative potrebbe impattare le tradizionali aree di focalizzazione di EMC, ma in realtà grazie alle Soluzioni che propone è in grado di offrire molto di piu’ rispetto ad approcci poco ottimizzati (Exchange – TCO) ,o troppo esposti sulla parte computazionale/prestazionale e meno sulle infrastrutture Storage (SAP HANA) , o che creano pericolosi “punti di Lock-in proprietari” (Oracle Exadata).
Da sempre invece la missione di EMC è e resta quella di affiancare il Cliente e di supportarlo nell’ottimizzazione di quanto ha già disponibile presso i propri Data Center, offrendo soluzioni all’avanguardia in tema di Virtualizzazione, Alta Affidabilità e Business Continuity, Prestazioni , Backup & Restore deduplicanti.
Inutile dire che avere sempre un’approccio ‘Consultant’ nei confronti dei Clienti permette di apparire seri e credibili anche quando si affrontano argomenti su ambiti non propriamente all’interno della propria sfera di competenza.
Eugenio Manini
eugenio.manini@emc.com



























{kind=link}